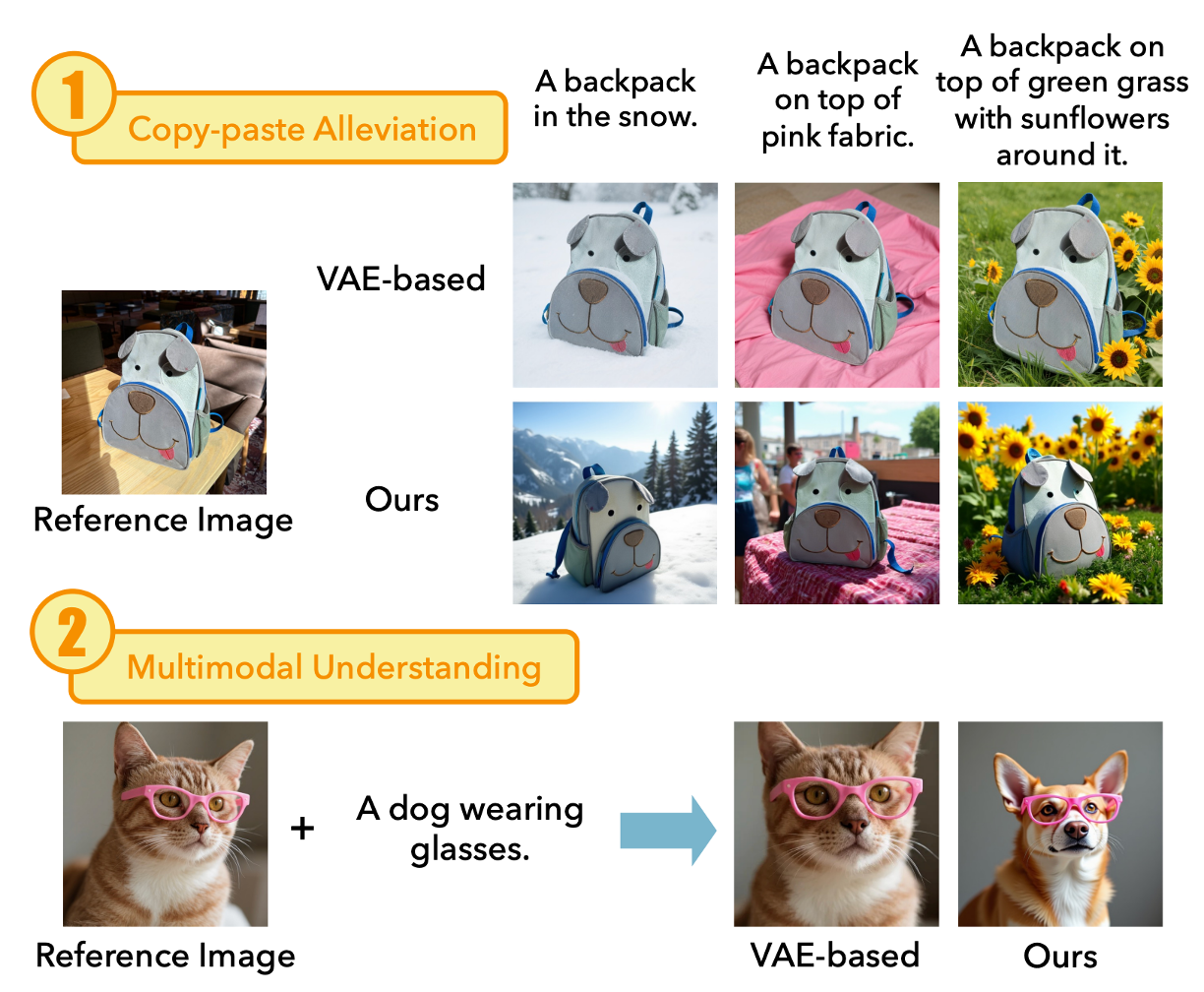
Subject-driven image generation aims to synthesize new images that preserve the identity of the given subject while following textual instructions. Existing approaches often encode text and reference images separately. This limits cross-modal reasoning abilities and causes copy-paste artifacts. Recent frameworks that connect multimodal models and diffusion models improve instruction following, but largely overlook identity preservation.
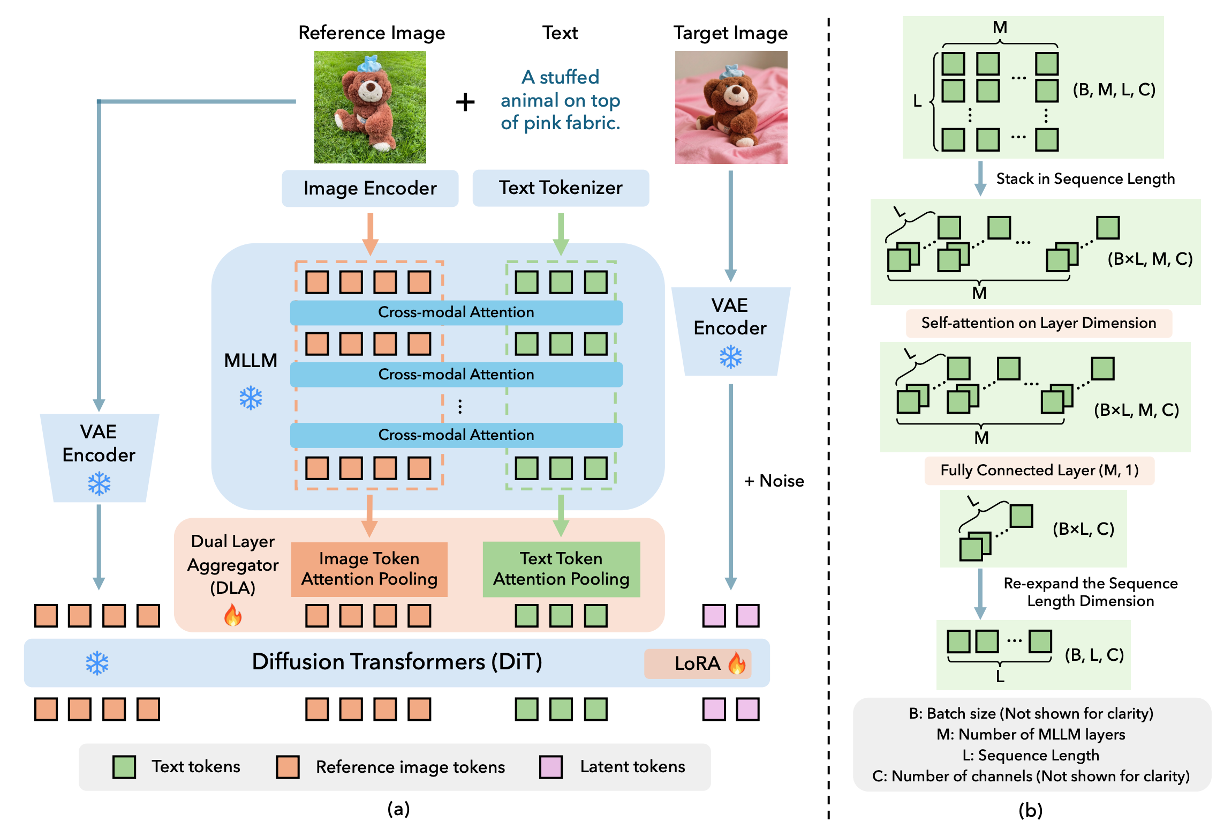
To address these limitations, we condition diffusion models on Multimodal Large Language Models (MLLMs) that jointly encode text and reference images, and augment it with VAE-based identity conditioning. A novel Dual Layer Aggregation (DLA) module is designed to aggregate multi-level MLLM features for optimal conditioning, and a multi-stage denoising strategy is applied to progressively balance the semantic information from MLLM and fine-detail identity from VAE during inference.
Extensive experiments demonstrate that our approach harmonizes multimodal understanding with identity preservation, mitigates copy-paste issues, and achieves superior performance regarding human preference on subject-driven image generation.