Multi-task visual learning is a critical aspect of computer vision.
Current research predominantly concentrates on the multi-task dense prediction setting,
which overlooks the intrinsic 3D world and its multi-view consistent structures, and lacks the
capacity for versatile imagination.
To address these limitations, we present a novel problem setting -- multi-task view synthesis (MTVS),
which reinterprets multi-task prediction as a set of novel-view synthesis tasks for multiple scene properties, including RGB.
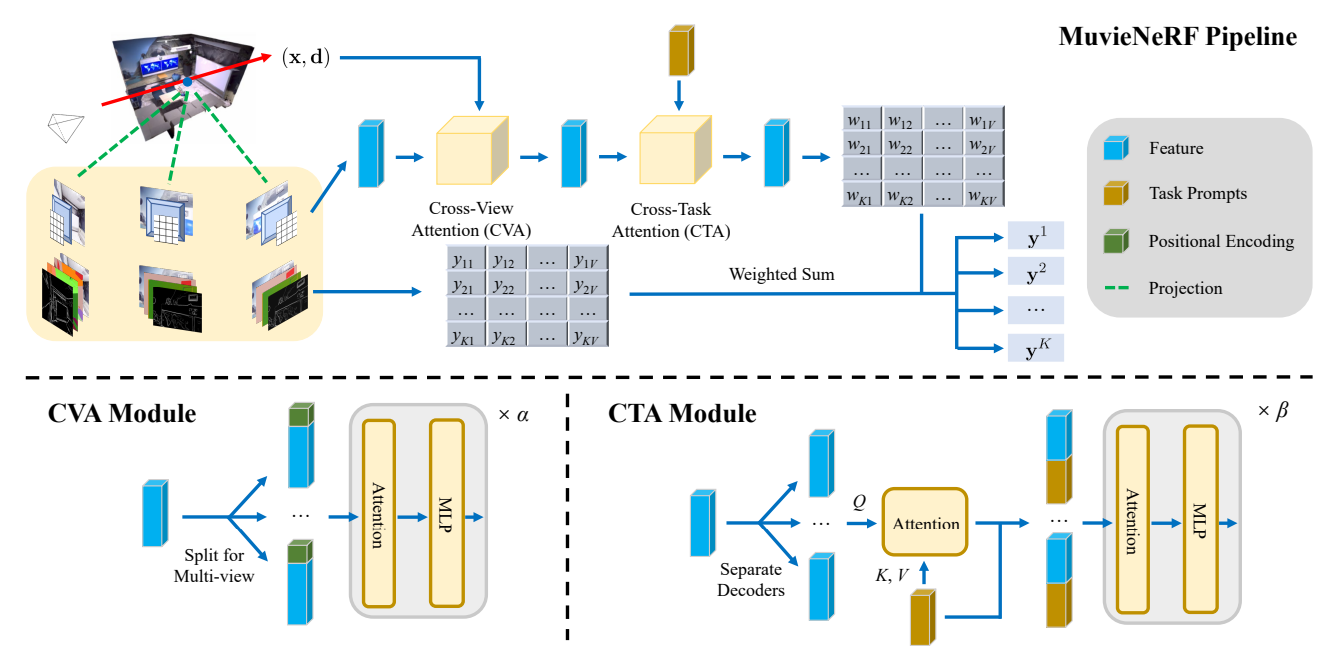
To tackle the MTVS problem, we propose MuvieNeRF, a framework that incorporates both multi-task and cross-view knowledge to simultaneously
synthesize multiple scene properties. \modelname integrates two key modules, the Cross-Task Attention (CTA) and Cross-View Attention (CVA) modules,
enabling the efficient use of information across multiple views and tasks.
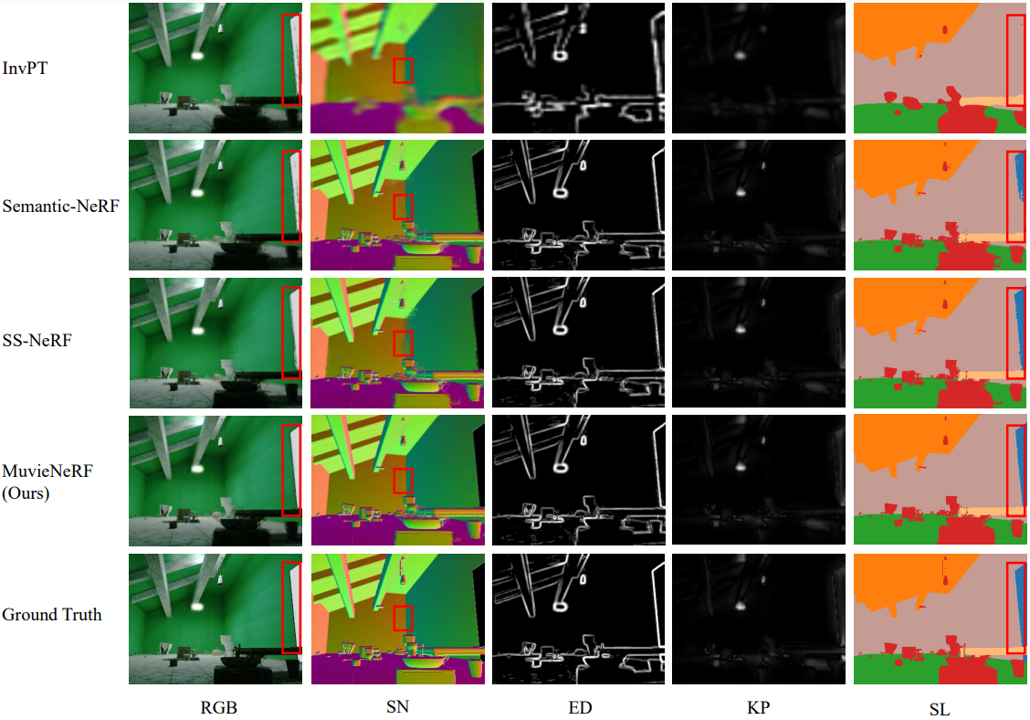
Extensive evaluations on both synthetic and realistic benchmarks demonstrate that MuvieNeRF is capable of simultaneously
synthesizing different scene properties with promising visual quality, even outperforming conventional discriminative models in various settings.
Notably, we show that MuvieNeRF exhibits universal applicability across a range of NeRF backbones.